
Mantener los sistemas críticos activos todo el tiempo es el objetivo de TI
El tiempo de inactividad golpea a las organizaciones de TI desde una multitud de fuentes.
Desde el desastre natural relativamente raro hasta los errores de usuario más comunes, ataques maliciosos o problemas de parches, los equipos de TI pueden garantizar que el tiempo de inactividad afectará a algunos de sus sistemas todos los años.
Y el coste de ese tiempo de inactividad puede ser alto, muy alto.
Para los sistemas que generan ingresos, se mide en miles de euros cada hora. Para los sistemas comerciales, la pérdida de productividad es igualmente costosa. Menos fáciles de definir son las pérdidas potenciales asociadas con la lealtad del cliente, insatisfacción del usuario final y posicionamiento competitivo.
Los sistemas de HA de Redestel permite a las organizaciones de TI mantener la máxima disponibilidad de sus servidores Windows y Linux al evitar el tiempo de inactividad y la pérdida de datos. El software hace esto mediante un mecanismo de replicación continua que mantiene una copia secundaria sin gravar el sistema primario o el ancho de banda de la red.
Con soporte para sistemas de origen o entornos de destino físicos, virtuales o en la nube, la solución de Redestel es una opción de replicación completa para organizaciones con entornos informáticos mixtos.
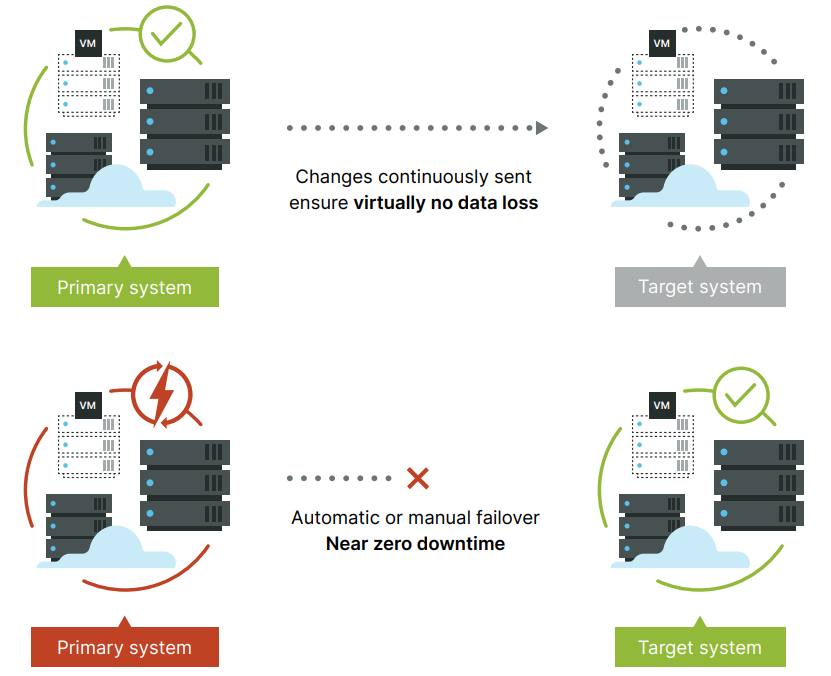
Sin demoras, sin pérdida de datos
El software replica continuamente los cambios del entorno de origen en un objetivo secundario en cualquier parte del mundo. Una vez que se completa la propagación inicial, los cambios se transmiten en tiempo real, lo que garantiza que la réplica esté sincronizada. El software replica archivos, aplicaciones o un servidor completo, incluida la configuración del sistema.
Las conmutaciones por error rápidas evitan el tiempo de inactividad.
En el caso de un desastre en un sistema o en todo un centro de datos, se puede invocar fácilmente una conmutación por error a la ubicación secundaria. Los sistemas secundarios se activan y los usuarios son redirigidos con solo unos segundos o minutos de interrupción.
Impacto insignificante en el rendimiento.
Los servidores de producción protegidos no experimentarán ninguna degradación del rendimiento debido a la replicación. Como los cambios se capturan y transmiten a nivel de byte, el impacto en el rendimiento de la red es mínimo.
Soporte de sistemas físicos.
Los sistemas físicos, que suelen ser críticos para las operaciones, a menudo se dejan fuera del plan de preparación para desastres. Para garantizar que todos los sistemas de TI estén protegidos, la solución de Alta Disponibilidad de Redestel puede replicar servidores Microsoft Windows o Linux en cualquier plataforma subyacente y en cualquier destino: físico, virtual o en la nube. Esto permite que TI unifique su solución de continuidad comercial en todas las plataformas en una única solución.
¿Cómo funciona?
La tecnología de replicación patentada se utiliza para capturar cambios a nivel de byte y replicarlos entre cualquier entorno de origen y destino: físico, virtual o en la nube.
Primero, la tecnología de replicación se implementa en todos los servidores que se protegen.
A través de la consola de administración, los entornos secundarios de destino se configuran y la replicación comienza con un proceso de inicialización. Todos los datos transmitidos se cifran mediante el cifrado AES-256 y se comprimen mediante tres niveles de mecanismos de ahorro de ancho de banda. Una vez que se completa la siembra, la solución actualiza el objetivo con cualquier cambio en tiempo real.
En caso de una interrupción, los administradores pueden conmutar por error de forma manual o automática a los usuarios al servidor secundario en minutos o segundos. El punto de recuperación puede ser el actual, o los sistemas pueden revertirse a un punto anterior, antes de que ocurriera un error o una infección.
Recuperación de desastres para sistemas críticos con poca tolerancia al tiempo de inactividad.
Cuando un sistema crítico se cae, ya sea por un ransomware, un desastre natural o un error humano, las empresas sufren pérdidas de ingresos y productividad hasta que se reanudan las operaciones normales. La forma más rápida de recuperarse es reubicar la carga de trabajo en otro servidor,
a menudo en una ubicación secundaria. Pero para la mayoría de las empresas, el hardware redundante, el espacio del centro de datos y los recursos de TI adicionales son demasiado costosos para que esta sea una opción viable, dejando a muchas pequeñas y medianas empresas sin preparación en caso de desastre. Con pocos recursos disponibles para gestionar un programa completo de recuperación de desastres, muchas empresas confían en el software de autoservicio para satisfacer sus necesidades básicas. Estas soluciones de autoservicio pueden ser eficaces para las empresas que pueden aplicar los ajustes de configuración adecuados y dedicar recursos a la gestión de un entorno de recuperación de desastres. Pero muchas empresas necesitan una opción más asistida que les ayude con la instalación, los informes, la auditoría, el cumplimiento y la gestión práctica en caso de que se produzca un desastre.
En lugar de vivir con el riesgo de un tiempo de inactividad inesperado, las empresas pueden confiar en Carbonite, que ofrece a las pequeñas y medianas empresas opciones para la recuperación de desastres que se ajustan a sus objetivos de recuperación y a los recursos que tienen -o pueden no tener- disponibles.
Recuperación de un desastre
Disaster Recover, que se ofrece como un servicio (as a Service) de software de recuperación ante desastres alojado en el Data Center del fabricante, reduce el riesgo de tiempo de inactividad inesperado al replicar de forma segura los sistemas críticos en la nube, proporcionando una copia actualizada para la conmutación por error cuando sea necesario.
La replicación desde el servidor principal a la nube ocurre continuamente a nivel de byte. Cuando hay una interrupción que alcanza un umbral de falla preestablecido, las empresas pueden conmutar inmediatamente al entorno secundario. El tiempo de inactividad total o RTO se mide en minutos, y el punto de recuperación, o RPO, se mide en segundos, eliminando virtualmente el impacto de la interrupción.
Al replicar de forma segura los sistemas críticos desde el entorno principal a la nube, el software garantiza que haya una copia actualizada disponible para la conmutación por error en cualquier momento, lo que minimiza el tiempo de inactividad y los costos.
Con un modelo de servicio, la empresa gestiona la instalación, las pruebas, los informes, la gestión y la conmutación por error ante desastres. El fabricante incluye pruebas de autoservicio no disruptivas e informes de conmutación por error que proporcionan pruebas de que los sistemas son recuperables, porque tener confianza en sus sistemas de protección de datos es una alta prioridad.
Recuperación de desastres gestionada contiene:
Al centrarse en estas áreas críticas de servicio, los clientes se beneficiarán de un equipo de soporte dedicado y experimentado por parte del fabricante, con soporte para auditoría de cumplimiento y certificación de la industria o necesidades de regulación. Además, el servicio incluye recuperación práctica de sistemas si es necesario, pruebas periódicas y actualizaciones a las últimas versiones de software.


